Main Results
We comprehensively evaluated four early-released Deep Research Agents alongside several leading LLMs with built-in web search capabilities. The evaluation employed both RACE and FACT frameworks to assess different aspects of agent performance.
| Model | RACE | FACT | |||||
|---|---|---|---|---|---|---|---|
| Overall | Comp. | Depth | Inst. | Read. | C. Acc. | E. Cit. | |
| LLM with Search Tools | |||||||
| Claude-3.7-Sonnet w/Search | 40.67 | 38.99 | 37.66 | 45.77 | 41.46 | 93.68 | 32.48 |
| Claude-3.5-Sonnet w/Search | 28.48 | 24.82 | 22.82 | 35.12 | 35.08 | 94.04 | 9.78 |
| Perplexity-Sonar-Reasoning-Pro(high) | 40.22 | 37.38 | 36.11 | 45.66 | 44.74 | 39.36 | 8.35 |
| Perplexity-Sonar-Reasoning(high) | 40.18 | 37.14 | 36.73 | 45.15 | 44.35 | 48.67 | 11.34 |
| Perplexity-Sonar-Pro(high) | 38.93 | 36.38 | 34.26 | 44.70 | 43.35 | 78.66 | 14.74 |
| Perplexity-Sonar(high) | 34.54 | 30.95 | 27.51 | 42.33 | 41.60 | 74.42 | 8.67 |
| Gemini-2.5-Pro-Grounding | 35.12 | 34.06 | 29.79 | 41.67 | 37.16 | 81.81 | 32.88 |
| Gemini-2.5-Flash-Grounding | 32.39 | 31.63 | 26.73 | 38.82 | 34.48 | 81.92 | 31.08 |
| GPT-4o-Search-Preview(high) | 35.10 | 31.99 | 27.57 | 43.17 | 41.23 | 88.41 | 4.79 |
| GPT-4o-Mini-Search-Preview(high) | 31.55 | 27.38 | 22.64 | 40.67 | 39.91 | 84.98 | 4.95 |
| GPT-4.1 w/Search(high) | 33.46 | 29.42 | 25.38 | 42.33 | 40.77 | 87.83 | 4.42 |
| GPT-4.1-mini w/Search(high) | 30.26 | 26.05 | 20.75 | 39.65 | 39.33 | 84.58 | 4.35 |
| Deep Research Agent | |||||||
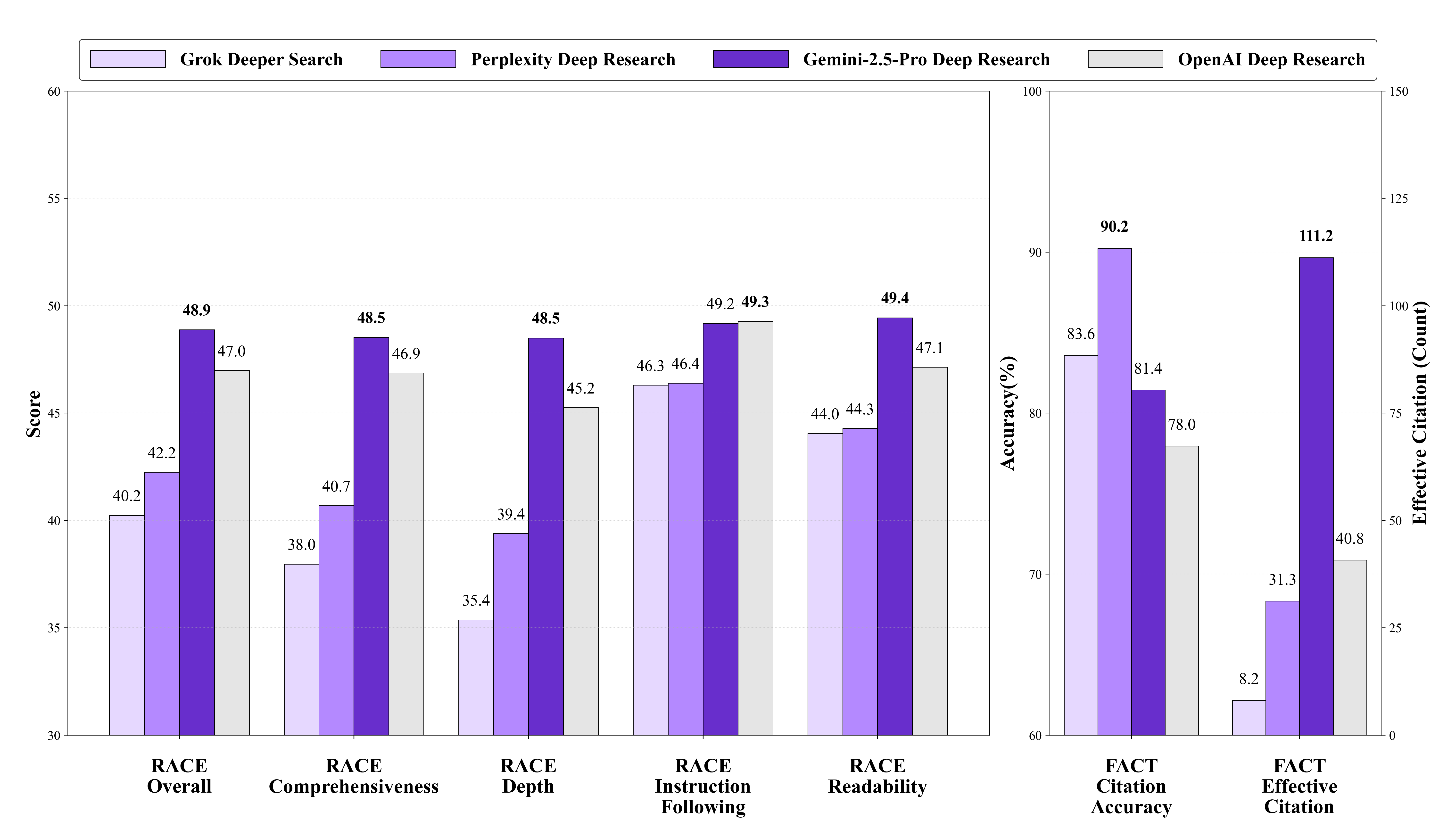
| Grok Deeper Search | 40.24 | 37.97 | 35.37 | 46.30 | 44.05 | 83.59 | 8.15 |
| Perplexity Deep Research | 42.25 | 40.69 | 39.39 | 46.40 | 44.28 | 90.24 | 31.26 |
| Gemini-2.5-Pro Deep Research | 48.88 | 48.53 | 48.50 | 49.18 | 49.44 | 81.44 | 111.21 |
| OpenAI Deep Research | 46.98 | 46.87 | 45.25 | 49.27 | 47.14 | 77.96 | 40.79 |
RACE Framework Results: Gemini-2.5-Pro Deep Research demonstrated leading overall performance (48.88) across all dimensions, with OpenAI Deep Research following closely (46.98). Notably, different models excelled in different dimensions--OpenAI Deep Research achieved the highest score in Instruction-Following (49.27), indicating that evaluation dimensions capture distinct capabilities.
FACT Framework Results: Deep Research Agents significantly outperformed LLMs with Search Tools in terms of Effective Citations. Gemini-2.5-Pro Deep Research achieved an exceptional 111.21 average effective citations, demonstrating superior information gathering capabilities. However, Perplexity Deep Research showed the highest Citation Accuracy (90.24%), indicating stronger precision in source attribution.